Presentata alla stampa pochi giorni fa durante l’E3, oggi debutta in pubblico la nuova ammiraglia delle schede grafiche targate Amd: si tratta della Radeon R9 Fury X. In questa breve anteprima vi presentiamo i primi dettagli del prodotto che rappresenta un punto di riferimento sotto il profilo tecnologico, mentre nel nostro laboratorio stiamo portando a termine i test più approfonditi relativi alle prestazioni. Sul prossimo numero di PC Professionale potrete leggere la prova corredata dall’analisi dell’architettura, della tecnologia HBM e completa di tutti i risultati sulle prestazioni.
 Basata sul processore grafico Fiji XT, la novità più importante che Amd ha introdotto con questo prodotto top di gamma riguarda l’utilizzo della tecnologia di memoria Hbm (High Bandwidth Memory). La Gpu Fiji XT è prodotta con processo tecnologico a 28 manometri, lo stesso impiegato per realizzare i processori grafici Amd di generazione precedente. In realtà la produzione del chip nel suo insieme è molto più complessa perché ora la memoria non è più esterna e saldata sul Pcb della scheda, ma è collocata a fianco della Gpu sul medesimo package.
Basata sul processore grafico Fiji XT, la novità più importante che Amd ha introdotto con questo prodotto top di gamma riguarda l’utilizzo della tecnologia di memoria Hbm (High Bandwidth Memory). La Gpu Fiji XT è prodotta con processo tecnologico a 28 manometri, lo stesso impiegato per realizzare i processori grafici Amd di generazione precedente. In realtà la produzione del chip nel suo insieme è molto più complessa perché ora la memoria non è più esterna e saldata sul Pcb della scheda, ma è collocata a fianco della Gpu sul medesimo package. 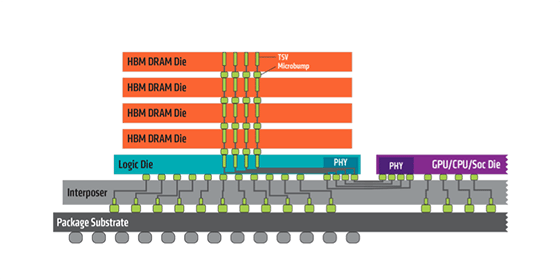 Il die del processore Fiji XT racchiude al suo interno 8,9 miliardi di transistor che servono alla sola architettura grafica, mentre dal computo mancano i transistor presenti nei chip di memoria HBM impilati al suo fianco. Si tratta di numeri impressionanti e che fanno intuire anche la necessità di utilizzare un sistema di raffreddamento a liquido per assicurare una temperatura di esercizio stabile e adatta a garantire la perfetta funzionalità della Gpu e delle memorie.
Il die del processore Fiji XT racchiude al suo interno 8,9 miliardi di transistor che servono alla sola architettura grafica, mentre dal computo mancano i transistor presenti nei chip di memoria HBM impilati al suo fianco. Si tratta di numeri impressionanti e che fanno intuire anche la necessità di utilizzare un sistema di raffreddamento a liquido per assicurare una temperatura di esercizio stabile e adatta a garantire la perfetta funzionalità della Gpu e delle memorie.  In tabella sono riportati i dati relativi alle caratteristiche tecniche della scheda che, almeno per il momento, è prodotta unicamente da Amd al fine di garantire la qualità e l’affidabilità con il nuovo chip.
In tabella sono riportati i dati relativi alle caratteristiche tecniche della scheda che, almeno per il momento, è prodotta unicamente da Amd al fine di garantire la qualità e l’affidabilità con il nuovo chip. 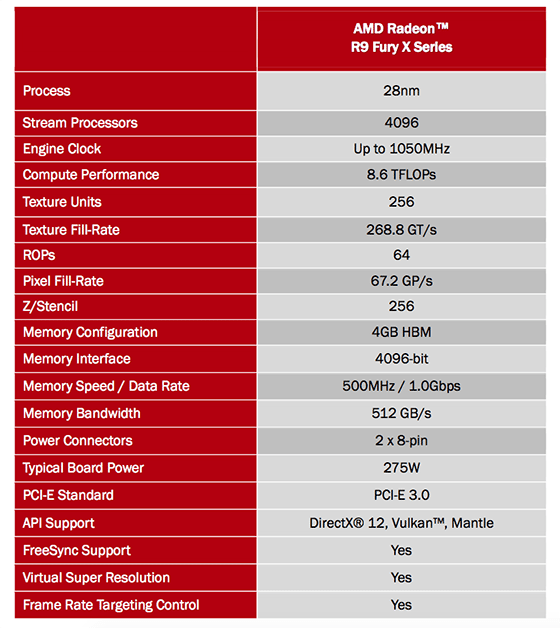

L’architettura Graphics Core Next
Introdotta per la prima volta alla fine del 2011, l’architettura Gcn (Graphic Core Next) è il fondamento delle ultime generazioni di processori grafici Amd. Questa architettura utilizza una struttura logica di base rappresentata dai moduli Gin Compute Unit che sono replicati all’interno del motore grafico in funzione del livello di prestazioni che si vuole raggiungere. Tali moduli sono rimasti pressoché inalterati dal punto di vista logico e funzionale, mentre si sono evoluti nel tempo a livello progettuale per garantire maggiori prestazioni, maggiore efficienza e per assicurare la compatibilità con le novità sul fronte delle librerie di programmazione, come ad esempio Mantle e le nuovissime DirectX 12. 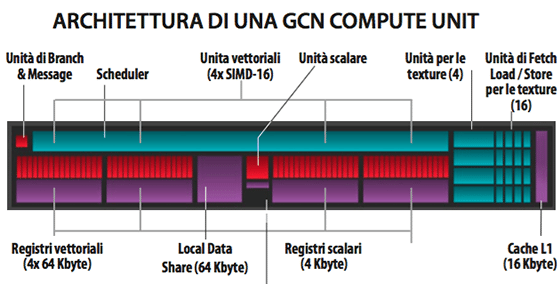 All’interno di ogni modulo sono presenti 64 stream processor organizzati in quattro unità vettoriali Simd (Single Instruction Multiple Data), una unità di calcolo scalare e quattro unità di texture; le unità di calcolo sono supportate da strutture di registri interni e da un sistema di cache. Ogni blocco di cache di primo livello (L1) serve un gruppo di quattro Gcn Compute Unit ed è ripartito in sezioni da 16 Kbyte per le istruzioni e da 32 Kbyte per i dati. Le cache di primo livello garantiscono una banda di trasferimento dati in modalità scrittura/lettura pari a 64 byte per ogni ciclo di clock. La cache di secondo livello (L2) è ripartita in blocchi funzionali con una banda di trasmissione dati pari a 64 Kbyte per ciclo di clock. La comunicazione e lo scambio dati tra i diversi gruppi di unità Gcn è garantita dalla Global Data Share, ovvero una cache condivisa accessibile da tutta le unità dell’architettura. I processori grafici sono realizzati assemblando tra loro una diversa quantità di moduli Gcn Compute Unit all’interno di un’organizzazione di alto livello definita Shader Engine, le unità Rop, il controller di memoria, il processore geometrico e il Command Processor. Il processore grafico Fiji XT utilizza l’ultima implementazione dell’architettura Gcn -identificata come Gcn 1.2 – e il numero delle Gcn Compute Unit pari a 64 e da questo deriva il conteggio finale di 4.096 stream o shader processor.
All’interno di ogni modulo sono presenti 64 stream processor organizzati in quattro unità vettoriali Simd (Single Instruction Multiple Data), una unità di calcolo scalare e quattro unità di texture; le unità di calcolo sono supportate da strutture di registri interni e da un sistema di cache. Ogni blocco di cache di primo livello (L1) serve un gruppo di quattro Gcn Compute Unit ed è ripartito in sezioni da 16 Kbyte per le istruzioni e da 32 Kbyte per i dati. Le cache di primo livello garantiscono una banda di trasferimento dati in modalità scrittura/lettura pari a 64 byte per ogni ciclo di clock. La cache di secondo livello (L2) è ripartita in blocchi funzionali con una banda di trasmissione dati pari a 64 Kbyte per ciclo di clock. La comunicazione e lo scambio dati tra i diversi gruppi di unità Gcn è garantita dalla Global Data Share, ovvero una cache condivisa accessibile da tutta le unità dell’architettura. I processori grafici sono realizzati assemblando tra loro una diversa quantità di moduli Gcn Compute Unit all’interno di un’organizzazione di alto livello definita Shader Engine, le unità Rop, il controller di memoria, il processore geometrico e il Command Processor. Il processore grafico Fiji XT utilizza l’ultima implementazione dell’architettura Gcn -identificata come Gcn 1.2 – e il numero delle Gcn Compute Unit pari a 64 e da questo deriva il conteggio finale di 4.096 stream o shader processor.
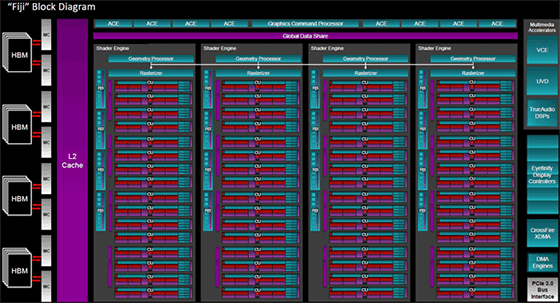
Memorie HBM La tecnologia di memoria HBM (High Bandwidth Memory) permette di impilare i chip per ottenere una maggiore densità di memoria rispetto alla superficie in pianta così da rendere possibile il posizionamento della memoria stessa sullo stesso package del processore al quale è collegata. Nel caso delle schede grafiche il confronto tra la memoria Gddr5 e quella Hbm evidenzia vantaggi sostanziali a favore di quest’ultima: primo tra tutti la possibilità di incrementare la quantità di memoria senza dover aumentare lo spazio necessario in pianta; in secondo luogo la tecnologia Hbm promette di offrire una banda di trasferimento dati pari a 100 Gbyte/s per ogni stack di chip contro i 28 Gbyte/s di un chip Gddr5. La tensione di alimentazione è inferiore (1,3 volt contro 1,5 volt) così come la frequenza operativa; la minor frequenza è compensata da un bus di trasferimento dati ampio 1.024 bit contro quello a 32 bit tipico dei chip Gddr5. La prima generazione di prodotti avrà però un limite di 4 Gbyte di memoria e dovremo aspettare la seconda generazione di prodotti prima di vedere schede grafiche con quantitativi maggiori di memoria Hbm.
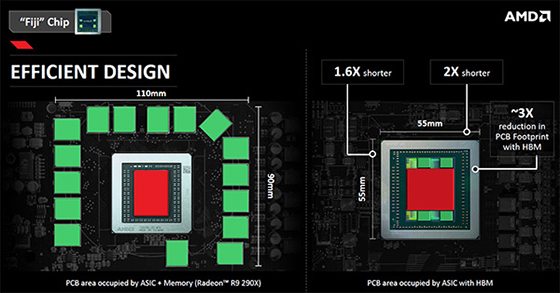
Come si può osservare dallo schema qui sopra, risulta evidente quanto sia vantaggioso utilizzare memorie di tipo HBM che permettono di ridurre in modo sensibile la dimensione e la complessità della scheda grafica nel suo complesso.
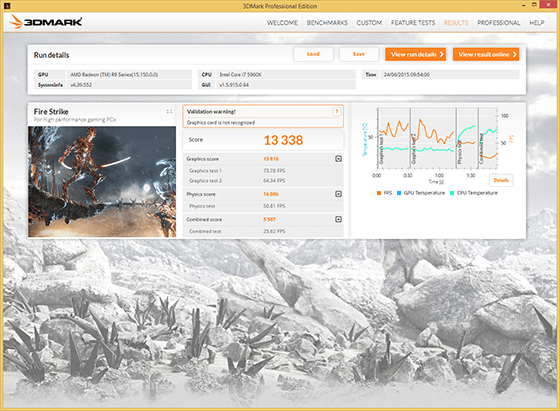
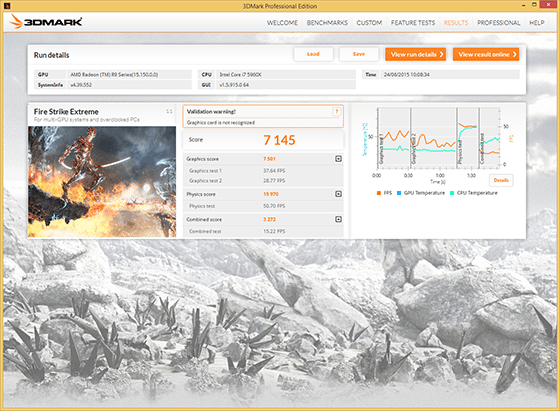
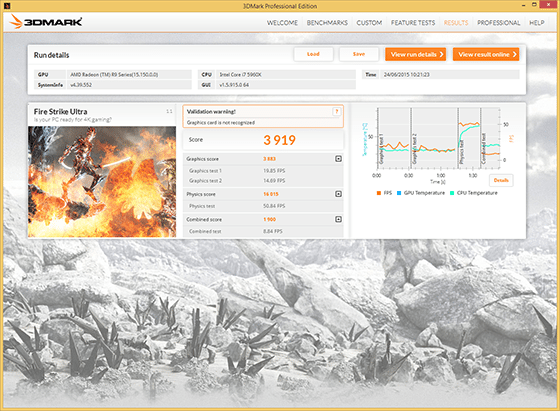
Le prestazioni
La Radeon R9 Fury X è ancora sotto test nel nostro laboratorio e stiamo raccogliendo e verificando i risultati nei diversi test. Di seguito pubblichiamo i primi risultati ottenuti che aggiorneremo man mano che avremo nuovi risultati.