

Intel svela i primi dettagli della nuova architettura mesh alla base della futura piattaforma Xeon Scalable Processor. A delineare i primi dettagli pubblici della nuova topologia mesh è Akhilesh Kumar, Principal Engineer in Datacenter Processor Architecture che opera all’interno del team Platform Engineering Group (PEG) dove guida i progetti delle architetture Skylake-SP e Cascade Lake. In un post pubblicato sul blog IT Peer Network di Intel, Akhilesh Kumar traccia le idee guida che hanno portato al cambiamento di maggior portata avvenuto negli ultimi anni all’interno delle architetture Intel.
Akhilesh Kumar sottolinea come la sfida di integrare un numero sempre maggiore di core per creare un processore multi core pone il problema di creare una interconnessione solida ed efficiente tra i core, la struttura della memoria e i sistemi di I/O. Queste interconnessioni funzionano come delle autostrade per le informazioni in transito e solo un corretto studio della topologia delle vie di comunicazione così come dei punti di ingresso e di uscita delle informazioni stesse permette di ottenere un traffico di dati scorrevole e che non impatti sulle prestazioni.
Il passaggio dai processori a singolo core a quelli con due, quattro, otto e più core ha portato alla nascita della topologia Ring Bus che ha debuttato nel 2011. La peculiarità del Ring Bus (bus ad anello) era quella di garantire un’elevata scalabilità della struttura di trasferimento dati al crescere degli agenti collegati ad essa. Con il termine agenti si identificano tutti i blocchi logici che hanno accesso al bus di comunicazione, ovvero i core, le cache, la sezione Uncore del processore e l’eventuale comparto grafico integrato.
Questa soluzione è stata la base sulla quale Intel ha espanso fino ad oggi le proprie architetture in modo semplice ed efficiente.
Pensate al Ring Bus come al percorso circolare di un treno, agli agenti come le stazioni presenti sulla linea e alle informazioni come ai passeggeri in transito. Sfruttando questa analogia è facile comprendere come l’aggiunta di una o più stazione lungo il percorso ha permesso di incrementare il numero dei core presenti nel processore senza dover apportare modifiche alla topologia dell’architettura stessa.
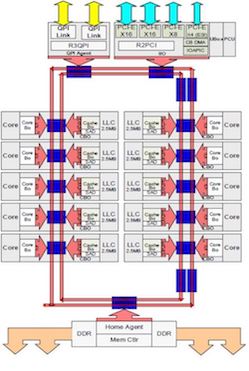
La topologia classica di un processore dotato di Ring Bus (in rosso) che permette di creare un anello che collega tra loro i diversi componenti dell’architettura.
Perché Intel ha deciso di abbandonare la topologia del Ring Bus e adottare un approccio diverso?
Il motivo è semplice da comprendere. Riprendendo l’analogia che abbiamo già utilizzato, per aumentare il numero di agenti presenti sul Ring Bus è necessario aumentare non solo il numero di stazioni, ma anche allungare il tragitto. Tutto ciò comporta una aumento del tempo necessario per trasferire le informazioni tra due agenti distanti tra loro, in modo simile a quanto accade ai passeggeri di un treno locale che è costretto a rallentare o addirittura a fermarsi in tutte le stazioni. Se il Ring Bus rimane una soluzione valida quando il numero degli agenti presenti sul suo percorso è limitato, ovvero nelle architetture con un basso numero di core (LCC, Low Core Count), non possiamo dire altrettanto per architetture che prevedono l’impiego di un numero molto alto di core.
Nei processori con elevato numero di core (HCC, High Core Count) Intel è stata costretta a impiegare due Ring Bus; da un lato questo ha permesso di semplificare la struttura dell’architettura e di mantenere un sistema di comunicazione efficiente all’interno dei singoli Ring Bus, ma dall’altro ha imposto l’utilizzo di complessi sistemi di switch per permettere lo scambio di informazioni tra un Ring Bus e l’altro.
Tutto ciò non ha avuto un impatto negativo solo sulla latenza nella movimentazione dei dati, ma ha richiesto anche di dedicare una fetta consistente del budget energetico del processore al funzionamento dell’infrastruttura di supporto, limitando di fatto le possibilità di sfruttare il budget energetico per incrementare le prestazioni delle unità di elaborazione.
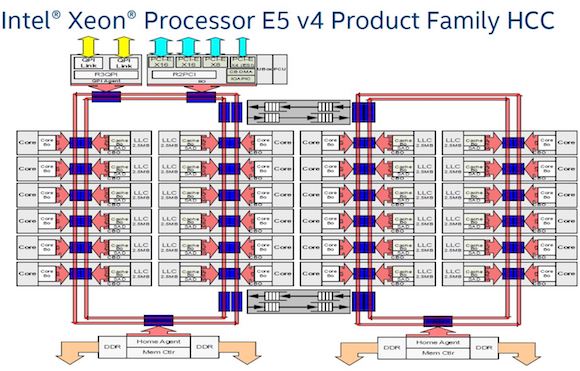
Nelle attuali architetture HCC due Ring Bus (in rosso) sono connessi tra loro per mezzo di switch dedicati che però incrementano la complessità dell’architettura e la latenza nello scambio di informazioni tra i diversi componenti del processore.
Per mantenere un’elevata efficienza nello scambio dati tra i diversi core e le altre strutture dell’architettura, Intel ha quindi deciso di adottare la nuova topologia mesh dove gli agenti si trovano in corrispondenza delle maglie di una griglia di connessioni. Questo permette di avere a disposizione più percorsi disponibili e percorsi più brevi per mettere in comunicazione elementi fisicamente lontani tra loro all’interno dell’architettura.
La struttura di tipo mesh migliora la latenza di comunicazione sia rispetto al caso peggiore, ovvero tra i core più distanti, sia rispetto alla media in quanto nella soluzione a griglia esistono più strade possibili per le informazioni. Ancora, la topologia di tipo mesh può scalare meglio di quella di precedente generazione all’aumentare del numero di core presenti nell’architettura stessa; in particolare i vantaggi dell’architettura mesh diventano più evidenti rispetto a quella Ring Bus via via che l’architettura diventa più complessa.
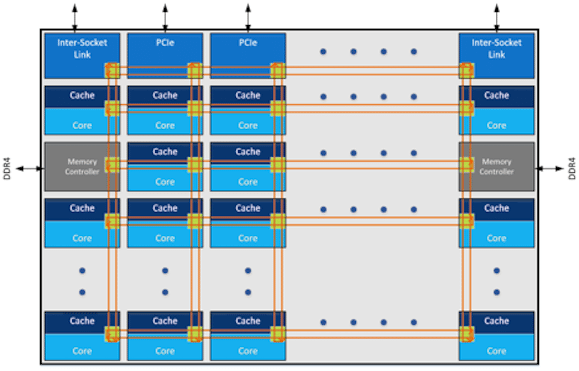
Nell’architettura mesh i singoli componenti si trovano sulle maglie di una griglia di connessioni che permette un traffico dati più efficiente e con latenze minori rispetto a quanto possibile con le soluzioni adottate fino ad oggi.
Osservando una delle prime immagini pubbliche che rivelano i dettagli dell’architettura mesh è possibile vedere come la nuova topologia utilizza connessioni orizzontali e verticali che mettono in comunicazione i core, le cache, la memoria e i controller I/O. Dal diagramma risulta evidente come questa topologia ha permesso di eliminare in modo completo gli switch, di mettere in comunicazione diretta tutti gli elementi dell’architettura e di consentire l’utilizzo di percorsi ottimizzati sfruttando le diverse intersezioni della griglia di connessioni.
L’impatto positivo in termini di latenza e banda di trasferimento tra i core si riflette in modo analogo anche sulla memoria, in quanto i controller sono collegati in modo diretto alla griglia. Per quanto riguarda le operazioni di I/O, le informazioni entrano ed escono dall’architettura mesh attraverso il bus Pci Express e connessioni inter socket dedicate.
I vantaggi dell’architettura mesh non si limitano a garantire una maggiore efficienza e una minore latenza nello scambio di informazioni, ma vanno ben oltre. Questa nuova topologia permette di incrementare la banda di trasmissione dati all’interno del processore tra i singoli core e tra questi e le unità di cache così come, i controller I/O e la memoria di sistema.
La nuova architettura mesh nasce per garantire fondamenta solide allo sviluppo delle future generazioni di processori per i datacenter dove la scalabilità , l’efficienza operativa ed energetica, la velocità delle trasmissioni dati e le latenza di accesso alle informazioni rivestono un ruolo primario per assicurare un miglioramento delle prestazioni da una generazione all’altra.