Oggi comincia ufficialmente l’era dei processori Ryzen della serie 3000 e della nuova piattaforma AMD caratterizzata da novità in tutti i comparti. I nuovi processori Ryzen sono veloci, molto veloci e anche molto efficienti dal punto di vista energetico. Con questa generazione di processori basati sulla terza iterazione della microarchitettura Zen, AMD non solo conferma la maturità di questo prodotto, ma soprattutto sorprende per lo scatto in avanti fatto da Ryzen.
Vai ai risultati e ai grafici della prova
Quest’anno AMD compie 50 anni ed è decisa a festeggiare alla grande. In poco più di due anni dal lancio della microarchitettura Zen, i successi conseguiti dalla famiglia Ryzen nel settore consumer e da quella EPYC nel settore enterprise hanno ridato lustro alla reputazione dell’azienda nel settore dei processori e riacceso la competizione con Intel. La conferma di tutto ciò è arrivata anche con il primo invito dell’organizzazione del Computex a tenere uno dei keynote di apertura della fiera. Prima al Computex e poi all’E3, Lisa Su – Ceo e presidente dall’ottobre del 2014 e di recente inserita tra gli amministratori delegati di maggior successo del 2019 – non ha mancato l’occasione per mettere in mostra le potenzialità attuali e future del portafoglio prodotti dell’azienda.

Sotto la guida di Lisa Su, le scelte e, come ha detto lei stessa, le scommesse fatte sullo sviluppo dei nuovi prodotti hanno permesso di salvare questa storica azienda da un declino che sembra senza vie di fuga. Oggi, invece, AMD ha riguadagnato quote di mercato e stretto partnership strategiche come quelle con Sony per la Playstation, con Microsoft per l’Xbox, con Google per la piattaforma Stadia, con Apple per tutta la gamma di computer e con Samsung per portare tecnologie della propria architettura grafica in ambito mobile.
Tra le scommesse figura anche quella dell’architettura a chiplet, alla base della nuova generazione di processori Ryzen ed EPYC; Lisa Su ha dichiarato che nel momento in cui l’azienda ha scelto questa strada “nessuno ci stava pensando”. Il Ceo ha aggiunto anche che “Crediamo che sia il percorso in cui dovrebbe andare il computing ad alte prestazioni. Così abbiamo fatto alcune chiamate e dato il via alle cose. Non puoi anticipare la tecnologia. Ci sono voluti cinque anni per costruire un nuovo core e dare al team il tempo e le risorse di cui avevano bisogno per farlo”.

La topologia MCM o l’architettura a chiplet che AMD ha deciso di adottare con i processori EPYC per il settore enterprise e con quelli Ryzen per il settore consumer – arriveranno anche i nuovi processori Threadripper molto simili a quelli EPYC – indica una strada che AMD, come Intel, intende sondare per il prossimo futuro. Le architetture eterogenee su singolo package sono propedeutiche per sviluppare quelle eterogenee in 3D. Pur adottando una architettura con tanti piccoli chiplet in un solo package 2D si avrebbero infatti limiti di superficie difficili da valicare: non è pensabile costruire package più grandi di quelli attuali e comunque si avrebbero alte latenze di comunicazione tra gli elementi più distanti. La soluzione potrebbe essere quella già adottata per le memoria HBM (High Bandwidth Memory) e per la tecnologia Intel Foveros: impilare i chiplet per contenere la superficie in pianta del package e ridurre al minimo le lunghezze delle interconnessioni.
Per vedere prodotti AMD con questo tipo di tecnologia ci vorranno probabilmente ancora diversi anni, mentre nel frattempo assisteremo alla piena maturazione del progetto Zen. AMD ha dichiarato che Zen 2 era stato prima pensato come uno shrink a 7 nanometri, ma l’azienda non si è tirata indietro quando si è presentata l’opportunità di sviluppare il progetto seguendo la strada innovativa che approfondiremo nelle prossime pagine. AMD ha così scelto TSMC per produrre i chiplet con i core a 7 manometri e Global Foundries per produrre il chiplet I/O a 12 e 14 nanometri.
Anche Zen 3 sarà prodotto con tecnologia a 7 nanometri e il suo sviluppo è ormai in uno stadio avanzato, mentre per i futuri Zen 4 e Zen 5 – anche questi già in fase di progettazione – non sono ancora stati stimati tempi di rilascio né tantomeno indicazioni su quale tipo di tecnologia potrà essere utilizzata per la loro produzione. Dopo il lancio dei primi modelli Ryzen della serie 3000, a settembre arriverà sul mercato il modello di punta Ryzen 9 3950X con sedici core e tra la fine di quest’anno e l’inizio del prossimo potremmo auspicare l’arrivo della nuova famiglia Threadripper. Questa sarà derivata dall’architettura Rome di EPYC e potrebbe portare sul mercato workstation processori con 64 core fisici; ciò sarà un elemento che potrebbe mettere pressione a Intel soprattutto nella competizione sui prezzi.
Arriveranno anche le Apu di nuova generazione, ma queste saranno indietro di una generazione come già in passato: sfrutteranno infatti i core Zen+ abbinati al comparto grafico Vega.

AMD Ryzen 9 3900X: dispone di 12 core fisici e può eseguire 24 thread in simultanea; è il primo processore Ryzen ha utilizzare due CCD nello stesso package. 
AMD Ryzen 7 3700X: dispone di 8 core fisici e può eseguire 16 thread in simultanea; è un Ryzen di fascia media come prezzo, ma estremamente competitivo dal punto di vista delle prestazioni. All’interno del package è presente un solo CCD.
Di seguito trovate tre tabelle che riassumo le caratteristiche dei processori Ryzen 9, Ryzen 7 e Ryzen 5; abbiamo riportato i modelli più interessanti delle tre generazioni prodotte da AMD: i Ryzen 9 sono solo basati su microarchitettura Zen 2 e al momento sono stati annunciati solo due modelli; i Ryzen 7 e i Ryzen 5 sono stati prodotti su tutte e tre le famiglie di microarchitettura Ryzen, ovvero Zen originale, Zen+ e Zen 2.
| CARATTERISTICHE RYZEN 9 | ||
|---|---|---|
| Modello | Ryzen 9 3950X | Ryzen 9 3900X |
| Socket | AM4 | AM4 |
| Architettura | Zen 2 | Zen 2 |
| Nome in codice | Matisse | Matisse |
| Tecnologia produttiva (nm) | 7 | 7 |
| Numero di transistor (milioni) | n.d. | n.d. |
| Dimensione del die (mm2) | n.d. | n.d. |
| Core / Thread | 16 / 32 | 12 / 24 |
| Frequenza base (MHz) | 3.500 | 3.800 |
| Frequenza turbo (MHz) | 4.700 | 4.600 |
| Frequenza XFR | n.d. | n.d. |
| Cache L1 (Kbyte) | 1.024 (16 x 64 Kbyte) | 768 (12 x 64 Kbyte) |
| Cache L2 (Mbyte) | 8 (16 x 512 Kbyte) | 6 (12 x 512 Kbyte) |
| Cache L3 (Mbyte) | 64 | 64 |
| Architettura GPU | No | No |
| Numero CU | n.a. | n.a. |
| Numero Stream Processor | n.a. | n.a. |
| Numero unità di texture | n.a. | n.a. |
| Numero unità ROP | n.a. | n.a. |
| Frequenza GPU (MHz) | n.a. | n.a. |
| Controller di memoria | DDR4 | DDR4 |
| Canali di memoria | 2 | 2 |
| Frequenza memoria (MHz) | da 1.866 a 3.200 | da 1.866 a 3.200 |
| Pci Express | 4.0 | 4.0 |
| Linee Pci Express | 16+4+4 | 16+4+4 |
| Tdp (watt) | 105 | 105 |
| Moltiplicatori sbloccati | Sì | Sì |
| AMD PurePower | Sì | Sì |
| AMD Precision Boost / versione | Sì / 2 | Sì / 2 |
| AMD XFR / versione | Sì / 2 | Sì / 2 |
| AMD Neural Net Prediction | Sì | Sì |
| AMD Smart Prefetch | Sì | Sì |
| AMD StoreMI | Sì | Sì |
| CARATTERISTICHE RYZEN 7 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Modello | Ryzen 7 3800X | Ryzen 7 3700X | Ryzen 7 2700X | Ryzen 7 2700 | Ryzen 7 2700E | Ryzen 7 1800X | Ryzen 7 1700X | Ryzen 7 1700 |
| Socket | AM4 | AM4 | AM4 | AM4 | AM4 | AM4 | AM4 | AM4 |
| Architettura | Zen 2 | Zen 2 | Zen+ | Zen+ | Zen+ | Zen | Zen | Zen |
| Nome in codice | Matisse | Matisse | Pinnacle Ridge | Pinnacle Ridge | Pinnacle Ridge | Summit Ridge | Summit Ridge | Summit Ridge |
| Tecnologia produttiva (nm) | 7 | 7 | 12LP | 12LP | 12LP | 14LPP | 14LPP | 14LPP |
| Numero di transistor (milioni) | n.d. | n.d. | 4800 | 4800 | 4800 | 4800 | 4800 | 4800 |
| Dimensione del die (mm2) | n.d. | n.d. | 192 | 192 | 192 | 192 | 192 | 192 |
| Core / Thread | 8 / 16 | 8 / 16 | 8 / 16 | 8 / 16 | 8 / 16 | 8 / 16 | 8 / 16 | 8 / 16 |
| Frequenza base (MHz) | 3.900 | 3.600 | 3.700 | 3.700 | 2.800 | 3.600 | 3.400 | 3.000 |
| Frequenza turbo (MHz) | 4.500 | 4.400 | 4.300 | 4.100 | 4.000 | 4.000 | 3.800 | 3.700 |
| Frequenza XFR | n.d. | n.d. | n.d. | n.d. | n.a. | 4.100 | 3.900 | 3.750 |
| Cache L1 (Kbyte) | 512 (8 x 64 Kbyte) | 512 (8 x 64 Kbyte) | 768 (8 x 96 Kbyte) | 768 (8 x 96 Kbyte) | 768 (8 x 96 Kbyte) | 768 (8 x 96 Kbyte) | 768 (8 x 96 Kbyte) | 768 (8 x 96 Kbyte) |
| Cache L2 (Mbyte) | 4 (8 x 512 Kbyte) | 4 (8 x 512 Kbyte) | 4 (8 x 512 Kbyte) | 4 (8 x 512 Kbyte) | 4 (8 x 512 Kbyte) | 4 (8 x 512 Kbyte) | 4 (8 x 512 Kbyte) | 4 (8 x 512 Kbyte) |
| Cache L3 (Mbyte) | 32 | 32 | 16 | 16 | 16 | 16 | 16 | 16 |
| Architettura GPU | No | No | No | No | No | No | No | No |
| Numero CU | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Numero Stream Processor | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Numero unità di texture | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Numero unità ROP | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Frequenza GPU (MHz) | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Controller di memoria | DDR4 | DDR4 | DDR4 | DDR4 | DDR4 | DDR4 | DDR4 | DDR4 |
| Canali di memoria | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Frequenza memoria (MHz) | da 1.866 a 3.200 | da 1.866 a 3.200 | da 1.866 a 2.933 | da 1.866 a 2.933 | da 1.866 a 2.933 | da 1.866 a 2.667 | da 1.866 a 2.667 | da 1.866 a 2.667 |
| Pci Express | 4.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| Linee Pci Express | 16+4+4 | 16+4+4 | 16+4 | 16+4 | 16+4 | 16 | 16 | 16 |
| Tdp (watt) | 105 | 65 | 105 | 65 | 45 | 95 | 95 | 65 |
| Moltiplicatori sbloccati | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| AMD PurePower | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| AMD Precision Boost / versione | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 1 | Sì / 1 | Sì / 1 |
| AMD XFR / versione | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 2 | No | Sì / 1 | Sì / 1 | Sì / 1 |
| AMD Neural Net Prediction | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| AMD Smart Prefetch | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| AMD StoreMI | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| CARATTERISTICHE RYZEN 5 | ||||||||
|---|---|---|---|---|---|---|---|---|
| Modello | Ryzen 5 3600X | Ryzen 5 3600 | Ryzen 5 2600X | Ryzen 5 2600 | Ryzen 5 2500X | Ryzen 5 1600X | Ryzen 5 1600 | Ryzen 5 1500X |
| Socket | AM4 | AM4 | AM4 | AM4 | AM4 | AM4 | AM4 | AM4 |
| Architettura | Zen 2 | Zen 2 | Zen+ | Zen+ | Zen+ | Zen | Zen | Zen |
| Nome in codice | Matisse | Matisse | Pinnacle Ridge | Pinnacle Ridge | Pinnacle Ridge | Summit Ridge | Summit Ridge | Summit Ridge |
| Tecnologia produttiva (nm) | 7 | 7 | 12LP | 12LP | 12LP | 14LPP | 14LPP | 14LPP |
| Numero di transistor (milioni) | n.d. | n.d. | 4.800 | 4.800 | 4.800 | 4.800 | 4.800 | 4.800 |
| Dimensione del die (mm2) | n.d. | n.d. | 192 | 192 | 192 | 192 | 192 | 192 |
| Core / Thread | 6 / 12 | 6 / 12 | 6 / 12 | 6 / 12 | 4 / 8 | 6 / 12 | 6 / 12 | 4 / 8 |
| Frequenza base (MHz) | 3.800 | 3.600 | 3.600 | 3.400 | 3.600 | 3.600 | 3.200 | 3.500 |
| Frequenza turbo (MHz) | 4.400 | 4.200 | 4.200 | 3.900 | 4.000 | 4.000 | 3.600 | 3.700 |
| Frequenza XFR | n.d. | n.d. | n.d. | n.d. | n.a. | 4.100 | 3.700 | 3.900 |
| Cache L1 (Kbyte) | 384 (6 x 64 Kbyte) | 384 (6 x 64 Kbyte) | 576 (6 x 96 Kbyte) | 576 (6 x 96 Kbyte) | 384 (4 x 96 Kbyte) | 576 (6 x 96 Kbyte) | 576 (6 x 96 Kbyte) | 384 (4 x 96 Kbyte) |
| Cache L2 (Mbyte) | 3 (6 x 512 Kbyte) | 3 (6 x 512 Kbyte) | 3 (6 x 512 Kbyte) | 3 (6 x 512 Kbyte) | 2 (4 x 512 Kbyte) | 3 (6 x 512 Kbyte) | 3 (6 x 512 Kbyte) | 2 (4 x 512 Kbyte) |
| Cache L3 (Mbyte) | 32 | 32 | 16 | 16 | 8 | 16 | 16 | 16 |
| Architettura GPU | No | No | No | No | No | No | No | No |
| Numero CU | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Numero Stream Processor | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Numero unità di texture | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Numero unità ROP | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Frequenza GPU (MHz) | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. | n.a. |
| Controller di memoria | DDR4 | DDR4 | DDR4 | DDR4 | DDR4 | DDR4 | DDR4 | DDR4 |
| Canali di memoria | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Frequenza memoria (MHz) | da 1.866 a 3.200 | da 1.866 a 3.200 | da 1.866 a 2.933 | da 1.866 a 2.933 | da 1.866 a 2.933 | da 1.866 a 2.667 | da 1.866 a 2.667 | da 1.866 a 2.667 |
| Pci Express | 4.0 | 4.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| Linee Pci Express | 16+4+4 | 16+4+4 | 16+4 | 16+4 | 16+4 | 16 | 16 | 16 |
| Tdp (watt) | 95 | 65 | 95 | 65 | 65 | 95 | 65 | 65 |
| Moltiplicatori sbloccati | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| AMD PurePower | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| AMD Precision Boost / versione | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 1 | Sì / 1 | Sì / 1 |
| AMD XFR / versione | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 2 | Sì / 1 | Sì / 1 | Sì / 1 |
| AMD Neural Net Prediction | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| AMD Smart Prefetch | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| AMD StoreMI | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
Architettura
La terza famiglia di processori Ryzen introduce numerosi cambiamenti rispetto alle generazioni precedenti e quelli più sostanziali riguardano la realizzazione e la topologia stessa dei processori: dal modello monolitico si passa infatti a quello modulare. Se nel primo caso tutti i circuiti sono realizzati su un singolo pezzo di silicio durante un’unico processo di fabbricazione, nell’approccio modulare adottato da AMD vengono separate in due chip distinti le funzioni I/O dalle unità di calcolo, pur mantenendo tutti i componenti all’interno di un solo package.

L’approccio MCM (Multi Chip Module) o Chiplet Design nel gergo che ora va per la maggiore non è una novità: l’abbiamo visto impiegato, ad esempio, nel 2007 da Intel nel caso dei Core 2 Quad (due die in un solo package) e più di recente dalla stessa AMD per la produzione dei processori EPYC per datacenter e Ryzen Threadripper per il segmento HEDT. I vantaggi della tecnica MCM sono la riduzione dei costi di produzione grazie alla minore dimensione dei singoli die in silicio e la maggiore resa produttiva: più il die è piccolo minore è la probabilità che presenti imperfezioni; questo combinato al maggior numero di die ottenibili da un singolo wafer permette di ridurre gli scarti di produzione rispetto a un progetto con die monolitico di grandi dimensioni. Uno svantaggio evidente, invece, consiste nel minor livello di prestazioni dovuto alle latenze per mettere in comunicazione moduli separati e nella maggiore complessità nel realizzare il substrato del package in cui montare più chip.
L’evoluzione tecnologica degli ultimi anni ha permesso di progettare substrati – il supporto che ospita i chiplet e le linee elettriche per alimentarli e tenerli in comunicazione – con prestazioni molto alte e sufficienti a ridurre in modo significativo le penalità indotte dall’impiego di un approccio modulare rispetto a quello monolitico. Tuttavia sussiste ancora una penalizzazione in termini di latenza quando si utilizzano comunicazioni tra chiplet distinti invece che tra componenti interne di uno stesso die monolitico.
Questo approccio – simile a quello intrapreso da Intel con il progetto Foveros – consente ad AMD di affrontare uno dei problemi legati alla miniaturizzazione sempre più spinta dei circuiti. Alcuni componenti, infatti, non scalano in modo ottimale nel passaggio a un processo produttivo che utilizza transistor e circuiti con un tasso di miniaturizzazione più elevato.
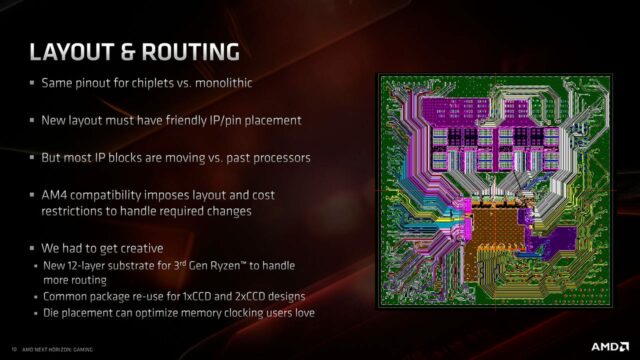
Se la tecnologia a 7 nanometri è ideale per la produzione dei core e delle cache presenti nei Core Chiplet Die, questo non è altrettanto vero per altri circuiti. Il controller di memoria, quello Pci Express e così via risultano più efficienti e performanti se realizzati con un processo produttivo meno estremo: nel caso dell’I/O Die dei Ryzen 3000 è stato scelto quello a 12 nanometri di GlobalFoundries, mentre per gli EPYC quello a 14 nanometri. In sostanza, l’utilizzo di chip eterogenei all’interno dello stesso package permette di avere ciascun componente realizzato con il processo produttivo che massimizza l’efficienza e le prestazioni.
Questa soluzione progettuale ha anche altri vantaggi: separando l’architettura in chiplet fisicamente distinti è possibile introdurre più rapidamente innovazioni tecniche – oppure apportare piccole correzioni – nel processore senza dover revisionare l’intero progetto. Ancora la divisione in chiplet asseconda la tendenza a muoversi verso architetture eterogenee che permettono di miscelare componenti diverse tra loro in un singolo package.

Nel nuovo progetto AMD possiamo identificare due tipologie di moduli: il primo è denominato CCD (Core Chiplet Die) e al suo interno racchiude fino a otto core di calcolo supportati da una struttura di cache completa e dall’interfaccia di comunicazione Infinity Fabric 2; questo chiplet è fabbricati con tecnologia produttiva a 7 nanometri negli stabilimenti TSMC. Il secondo tipo di modulo è denominato I/O Die e racchiude tutti i controller per gestire le funzioni I/O del processore, le connessioni Infinity Fabric 2 e il controller di memoria; questo modulo è fabbricato negli stabilimenti Global Foundries con tecnologia produttiva a 12 nanometri.
Detto ciò passiamo alla disamina delle caratteristiche delle soluzioni basate sulla microarchitettura Zen 2 partendo dal singolo core fino a giungere al processore completo.
Core, CCX e CCD
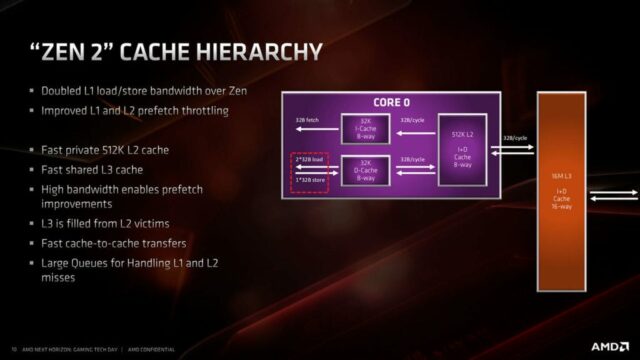
Pur presentando una microarchitettura con lo stesso impianto di quella Zen originale, la nuova Zen 2 permette di avere core più efficienti sotto il profilo energetico e capaci al tempo stesso di elaborare un maggior numero di istruzioni. A livello macroscopico i core appaiono molto simili al passato e le differenze di maggior rilievo includono l’introduzione di un nuovo sistema di predizione dei salti per la cache L2 (TAGE predictor), il raddoppio della cache micro-op, il raddoppio della cache L3, un aumento delle risorse per le operazioni sugli interi, un aumento delle risorse relative alle operazioni Load/Store e il supporto per la gestione di singole operazioni AVX2.

Ogni core è equipaggiato con una cache L1 – 32 Kbyte per le istruzioni (L1-I) e 32 Kbyte per i dati (L1-D) – e una cache L2 ampia 512 Kbyte. La modifica più evidente con le precedenti microarchitetture Zen risiede nel dimezzamento della cache L1-I e nel raddoppio della sua associatività: 32 Kbyte 8-way rispetto ai precedenti 64 Kbyte 4-way. Sebbene la riduzione della dimensione della L1-I sia compensata in parte dalla maggiore flessibilità offerta da una associativi maggiore, i due effetti non si elidono a vicenda. Tuttavia lo spazio risparmiato con la riduzione in dimensioni della L1-I ha permesso ai progettisti AMD di raddoppiare la dimensione della cache micro-op.
Il risultato è che da un lato la cache L1-I risulta più efficiente e più utilizzata essendo il suo spazio minore di quello precedente, mentre dall’altro lato la maggiore cache micro-op consente di parcheggiare un maggior numero di istruzioni già decodificate e quindi di poter bypassare la fase di decodifica delle istruzioni molto più spesso. Stando a quanto dichiarato, la nuova configurazione delle cache L1-I e quella della cache micro-op sono in grado di offrire una maggiore efficienza e maggiori prestazioni.
Le cache L1 e L2 operano ancora in modalità write back; tale meccanismo prevede l’aggiornamento dei dati solo all’interno della cache e la scrittura in memoria se e quando necessario; ciò permette di ottenere una latenza di accesso minore e una maggiore disponibilità di banda per la trasmissione dei dati.
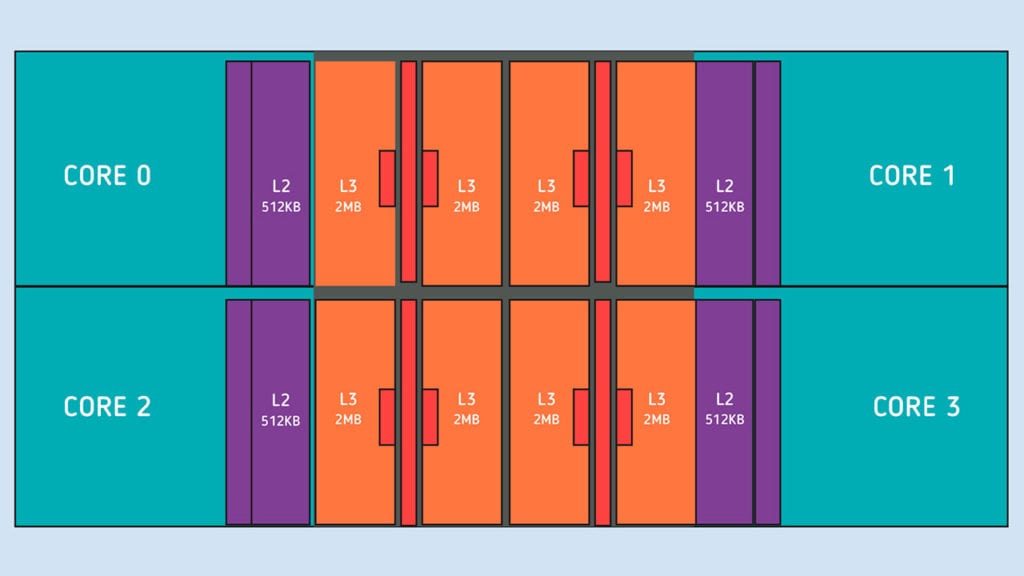
A valle della struttura delle cache troviamo la L3 condivisa tra i quattro core accorpati all’interno di un unico blocco denominato CCX (Core Complexs). Rispetto alle precedenti generazioni Zen e Zen+, l’attuale architettura Zen 2 integra il doppio della cache L3: 16 Mbyte 16-way contro gli 8 Mbyte 16-way.
La modalità operativa della L3 è rimasta di tipo victim cache come per le precedenti generazioni Zen; ciò significa che le informazioni contenute in questa cache sono quelle rimosse dalla L2 per fare posto a dati necessari alle operazioni del core di calcolo. La cache L3 è utilizzata come parcheggio per le informazioni presenti in quelle zone della cache L2 che devono essere rese disponibili per caricare altri dati; non è quindi utilizzata per il transito di dati dalla memoria di sistema verso il processore, ma solo come parcheggio per le informazioni presenti nella L2.
La cache L3, infatti, non è utilizzata per il transito dei dati dalla memoria di sistema verso la cache L2: nel caso di un cache miss sulla L2 e sulla L3 – questa viene controllata per verificare la presenza delle informazioni richieste qualora non siano presenti nella L2 – i dati sono caricati direttamente dalla memoria di sistema all’interno della cache L2. Per fare posto a queste informazioni il contenuto corrispondente alla zona della L2 impiegata nell’operazione viene copiato nella L3. L’approccio victim cache permette di eliminare la ridondanza dei dati presenti nella cache L3 che in questo modo contiene solo quelle informazioni che non possono essere trattenute nella cache di secondo livello.
La microarchitettura dei core Zen 2 implementa la tecnologia SMT (Simultaneous Multi-Threading) che permette di raddoppiare il numero dei thread eseguibili in simultanea come avviene, in modo simile, con la tecnologia Hyper-Threading di Intel.
Come nelle soluzioni di precedente generazione, più core di calcolo sono utilizzati per dare vita a un’architettura multi core il cui modulo di base è denominato CCX (Core Complexes). Tale modulo contiene quattro core assemblati tra loro in un unico gruppo supportato dalla presenza della cache L3 di tipo condiviso. Due blocchi CCX sono quindi assemblati all’interno del Core Chiplet Die (CCD) e comunicano tra loro per mezzo di una connessione Infinity Fabric di seconda generazione. Quest’ultima è utilizzata anche canale di comunicazione tra più CCD e il resto dell’architettura del processore passando attraverso il componente I/O Die; i CCD non hanno infatti connessioni dirette tra loro.
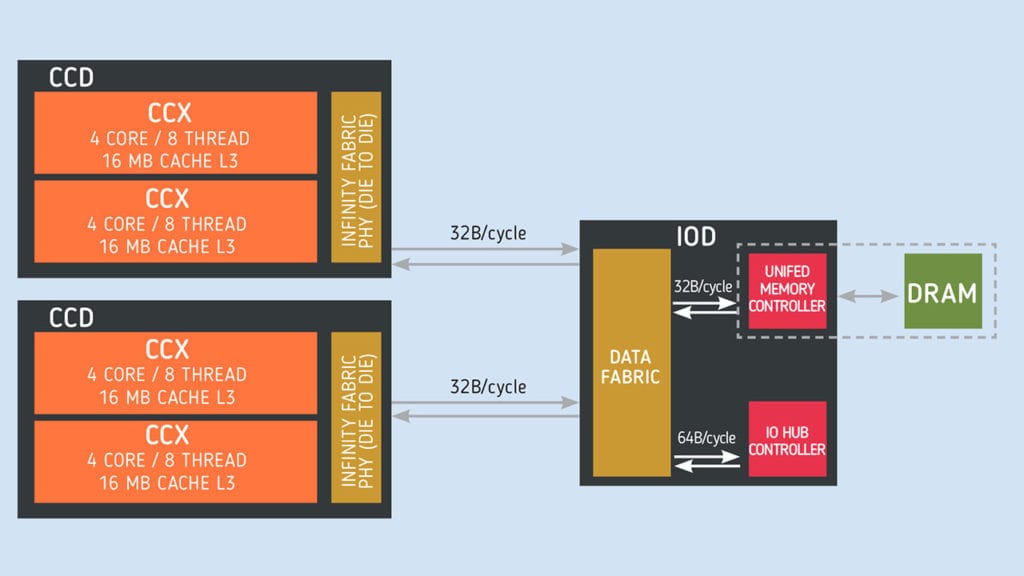
Ottimizzazioni
AMD e Microsoft hanno lavorato a stretto contatto per mettere in campo le ottimizzazioni necessarie per permettere a Window di sfruttare in modo ottimale la microarchcitettura Zen 2 e in modo particolare la nuova topologia dei processori Ryzen della serie 3000. Tali ottimizzazioni richiedono sono presenti nel primo aggiornamento di Windows per il 2019 – denominato 1903 – prevedono un approccio su due fronti: quello relativo alla gestione dei thread (Thread Grouping) e alla gestione delle frequenze operative (Clock Ramping).
Il software moderno e in modo particolare quello dei videogiochi tende a generare thread multipli invece che appoggiarsi a un singolo thread. Poiché questi thread hanno necessità di comunicare tra loro, AMD ha deciso di adottare l’approccio Thread Grouping al posto di quello Hybrid thread expansion adottato fino a questo momento. Ciò significa che i thread andranno ad occupare tutti i core di un singolo CCX prima di accedere e utilizzare le risorse di un altro CCX. AMD ritiene che questo approccio, sebbene possa determinare l’insorgere di concentrazioni di consumo e calore all’interno di un Core Chiplet Die, valga la pena di essere utilizzato per offrire un incremento di prestazioni a livello generale.

La seconda ottimizzazione – questa richiede sia un aggiornamento del bios sia l’utilizzo di Windows 10 May 10th Update – denominata Clock Ramping permette al processore di salire di frequenza in modo molto più rapido rispetto al passato. Pur avendo un’elevata granularità all’interno del proprio intervallo di frequenze – AMD prevede incrementi di 25 MHz tra i diversi stati del processore – il cambio di frequenza era ben più lento rispetto a quanto è riuscita a fare Intel con i proprio processori. La tecnica adottata da AMD – denominata CPPC2, ovvero Collaborative Power Performance Control 2 – consente al processore di ridurre il tempo di innalzamento della frequenza operativa da 30 millisecondi a soli 1 o 2 millisecondi (contro i circa 15 millisecondi caratteristici dei processori Intel di classe Kaby Lake). La tecnologia CPPC2 opera in modo simile a quella Speed Shift di Intel, dove è il processore a gestire in modo autonomo i diversi stati energetici e di frequenza in modo indipendente dal sistema operativo. Stando a a quanto dichiarato da AMD, questa nuova gestione delle frequenze è in grado di offrire miglioramenti significativi nell’avvio delle applicazioni.
Un altro sistema adottato per migliorare le prestazioni consiste nell’introdurre istruzioni specifiche per gestire in modo ottimizzato alcuni scenari; con Zen 2 i progettisti AMD hanno aggiunto tre istruzioni destinate a gestire tre diversi situazioni. L’istruzione CLWB permette di programmi di spingere indietro i dati verso la memoria non voltatile per prevenire la perdita di informazioni qualora il sistema riceva un comando di alt. La seconda istruzione per le cache, indicata come WBNOINVD, è stata sviluppata per prevedere quando una particolare porzione della cache potrebbe essere richiesta dal codice in esecuzione e provvedere così alla sua pulizia in modo che sia pronta nel momento del bisogno. Questa tecnica permette di ridurre la latenza dovuta all’esecuzione di un comando di pulizia della cache quando ormai l’istruzione è pronta per essere eseguita all’interno della pipeline.
Il terzo set di istruzioni è racchiuso sotto l’ombrello QoS – Quality of Service – è serve alla gestione delle priorità di utilizzo delle cache e della memoria. Le istruzioni QoS permettono di riservare risorse o di prevenire il completo assorbimento di esse da parte di un processo in esecuzione, come ad esempio una macchina virtuale.
I/O Die
Un processore completo, indipendentemente dal numero di Core Chiplet Die utilizzati, impiega un singolo modulo deputato alla gestione al comparto I/O e denominato I/O Die. All’interno di questo chiplet sono presenti il sistema di connessione proprietario Infinity Fabric di seconda generazione, un controller Pci Express 4.0, un controller Usb e un controller di memoria Ddr4 a doppio canale con supporto a moduli Ddr4-3200.
Innanzitutto l’Infinity Fabric serve come sistema di collegamento tra i singoli Core Chiplet Die e l’I/O Die, così che i core abbiano accesso a tutte le risorse del sistema. In secondo luogo, nei processori che integrano più Core Chiplet Die questi possono comunicare tra loro passando attraverso l’I/O Die grazie alla connessione Infinity Fabric.
Il controller Pci Express 4.0 presente nell’I/O Die è in grado di gestire 24 linee di comunicazione: 16 linee sono dedicate alla connessione con la scheda grafica, 4 sono dedicate al supporto di unità di archiviazione con tecnologia NVMe e 4 servono da canale di comunicazione tra il processore e il chipset. A fianco del controller Pci Express 4.0 è presente un controller Usb in grado di gestire 4 porte Usb 3.2 Gen 2.
Ryzen serie 3000
I Ryzen della serie 3000 – nome in codice Matisse – saranno offerti con uno o due Core Chiplet Die per un massimo di 16 core. I modelli con un massimo di 8 core utilizzano un solo CCD e vanno a costituire l’offerta Ryzen 3, Ryzen 5 e Ryzen 7 di nuova generazione.
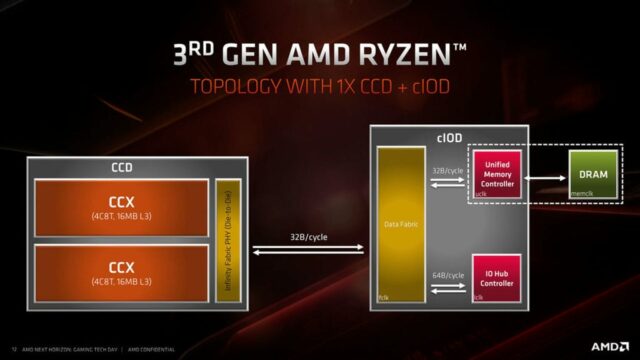
I modelli Ryzen 9 saranno quelli con più di 8 core e utilizzeranno una topologia con due CCD e un I/O Die. Il Ryzen 9 3900X disponibile già da luglio offre un totale di 12 core fisici, ottenuti disabilitando quattro core all’interno di ciascun CCD. Il modello top di gamma Ryzen 9 3950X, in arrivo a settembre, metterà a disposizione tutti i 16 core presenti nell’architettura e rappresenterà la punta di diamante dell’offerta AMD nel settore consumer.
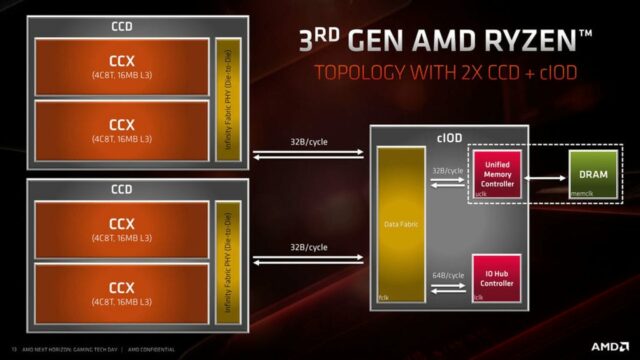
All’interno del package di ogni Ryzen di terza generazione è presente il medesimo chip I/O e ciò significa che tutti i nuovi processori dispongono di 24 linee Pci Express 4.0 e di un controller di memoria a doppio canale. Come in passato sarà possibile intervenire sulle frequenze operative per portare i processori oltre la soglia delle impostazioni di progetto per spremere fino all’ultimo megahertz di frequenza. Tuttavia, grazie alle tecnologie Precision Boost 2 e XFR anche l’utente comune potrà beneficiare di sistemi automatici per ottenere il massimo delle prestazioni garantite dalle specifiche di progetto.

I Ryzen 3000 utilizzano il socket AM4 come le precedenti generazioni e molte schede madri di fascia alta basate sul chipset AMD X470 potranno essere utilizzate per sfruttare i nuovi processori. Tuttavia, alcune funzioni saranno disponibili solo abbinando al processore una delle schede madri basate sulla nuova generazione di chipset AMD X570.
I prezzi dei nuovi Ryzen – al momento possiamo basarci solo su quelli ufficiali ma in dollari americani – sono estreamente allettanti in quanto permettono di ottenere prestazioni elevate con costi contenuti o comunque molto concorrenziali. A costare di più rispetto al passato saranno le schede madri: pagheremo un sovrapprezzo per il Pci Express 4.0, ma anche per la maggiore quantità di funzioni disponibili rispetto al passato..
Piattaforma
Insieme alla terza generazione di processori Ryzen debuttano anche il nuovo chipset AMD X570 e una serie di schede madri aggiornate. Queste non sono strettamente necessarie per utilizzare i processori Ryzen della serie 3000, ma introducono novità tecnologiche interessanti. Prima tra tutte il supporto al Pci Express 4.0 che potrà essere sfruttato solo con un sistema assemblato utilizzando un processore Ryzen serie 3000 e una scheda madre con chipset X570.
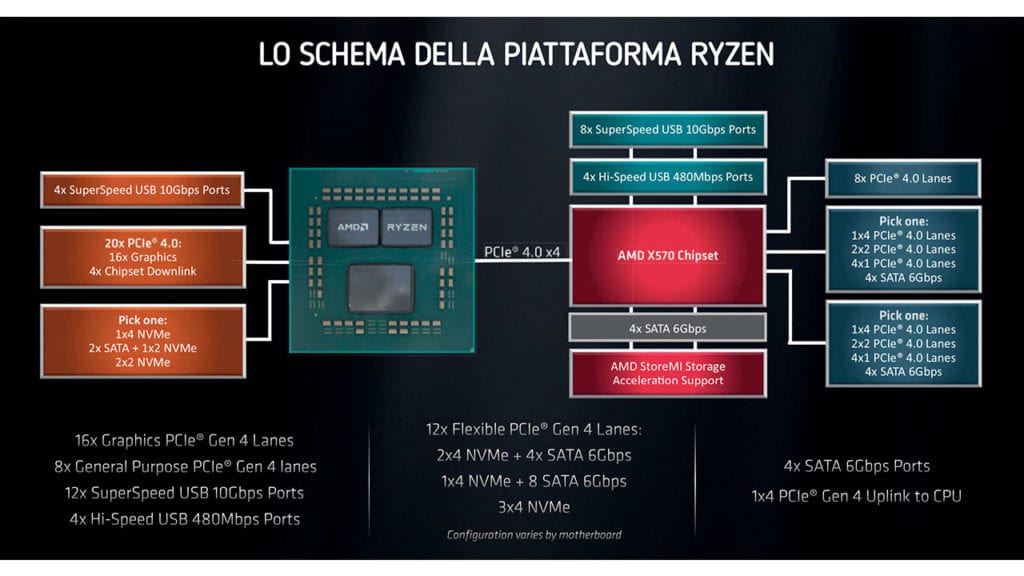
La tecnologia Poi Express 4.0 raddoppia il transfer rate e la banda di trasferimento dati rispetto alla tecnologia PCI Express 3.0: il transfer rate passa da 8 GT/s a 16 GT/s, mentre la banda di trasmissione dati massima teorica permette velocità fino 31,5 Gbyte/s su connessioni PCI Express 4.0 x16 contro i 15,8 Gbyte/s consentite dal PCI Express 3.0 sullo stesso tipo di connessione. Ciò significa avere a disposizione maggiore banda quando si considerano connessioni che utilizzano lo stesso numero di linee oppure avere la possibilità di ottenere la stessa capacità di trasmissione con la metà delle linee elettriche.
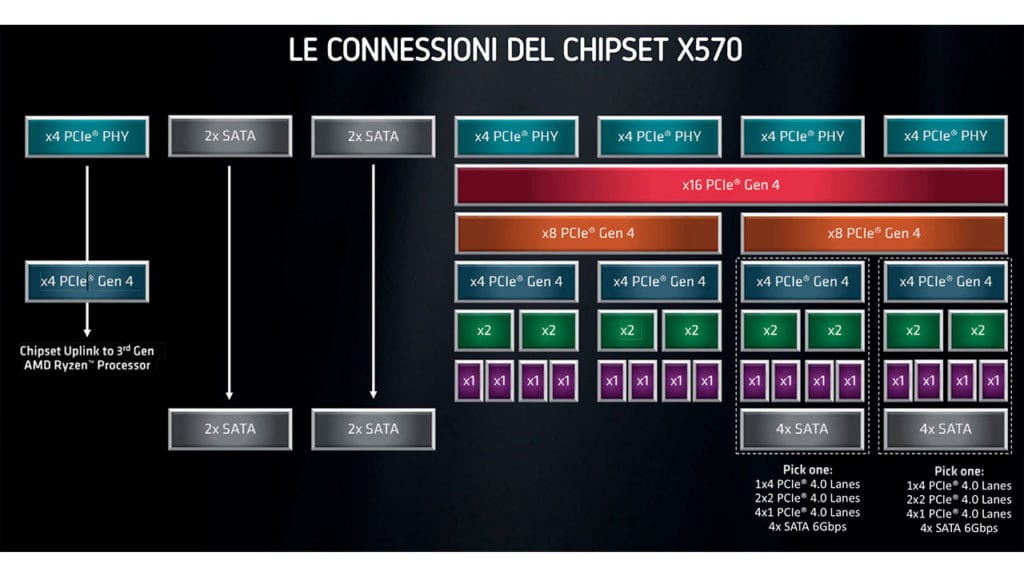
Nel caso del chipset, il cui progetto è derivato in parte da quello dell’I/O Die integrato nei processori Ryzen della serie 3000, quattro linee Pci Express sono dedicate al canale di comunicazione tra il processore e il chipset stesso. Oltre a queste sono disponibili altre 16 linee PCI Express 4.0 che possono essere configurate a seconda delle esigenze: nello specifico 8 di queste linee possono essere utilizzate per creare combinazioni differenti sfruttano le modalità x8, x4, x2 e x1. Le altre 8 linee PCI Express 4.0 possono essere utilizzate in modo analogo oppure utilizzate per collegare controller Sata aggiuntivi; due controller Sata per un totale di quatto connessioni con supporto alla tecnologia StoreMI sono infatti già presenti nel chipset. Il chipset AMD X570 è in grado di gestire inoltre 8 porte Usb 3.2 Gen 2 e 4 porte Usb 2.0 per un totale di 12 porte Usb.
Socket AM4
Al pari delle piattaforme compatibili con i processori basati su Zen e Zen+, anche quelle per i processori basati su Zen 2 utilizzano il socket AM4. Ciò significa che i processori Ryzen della serie 3000 possono – in molti casi ma non in tutti – essere utilizzati sulle schede madri con socket AM4 esistenti grazie all’aggiornamento del bios. Ciò significa inoltre che la nuova generazione di schede madri dovrebbe supportare sia la prima sia la seconda generazione di processori Ryzen.
| Compatibilità tra chipset e processori | |||||
|---|---|---|---|---|---|
| Ryzen serie 1000 | Ryzen serie 200 | Ryzen serie 3000 | |||
| CPU | CPU | APU | CPU | APU | |
| X570 | No | Sì | No | Sì | Sì |
| X470 | Sì | Sì | Sì | Sì | Sì |
| B450 | Sì | Sì | Sì | Sì | Sì |
| X370 | Sì | Sì | Sì | Beta Bios | Sì |
| B350 | Sì | Sì | Sì | Beta Bios | Sì |
| A320 | Sì | Sì | Sì | No | Sì |
Nel primo caso uno degli elementi discriminanti deriva dal maggior numero di core presenti nella nuova generazione di processori Ryzen e nella maggior richiesta di potenza in condizioni di pieno carico. Ciò significa che solo le schede madre dotate di un adeguato circuito di alimentazione (Vrm) potranno essere rese compatibili con l’aggiornamento del bios.
AMD dovrebbe continuare lo sviluppo dei processori Ryzen su socket AM4 almeno per tutto il 2020 e questo dovrebbe garantire la compatibilità con un’eventuale famiglia di processori Ryzen della serie 4000 basata sulla possibile ottimizzazione della microarchitettura Zen 2 in una plausibile Zen 2+. Non esistono ancora indicazioni sulla futura piattaforma per i processori che utilizzeranno la microarchitettura Zen 3 e che dovrebbero arrivare sul mercato non prima del 2021.

MSI MEG X570 Godlike 
Asus ROG Crosshair VIII Hero WiFi
La prova sul campo
Nel corso delle presentazioni che hanno preceduto il lancio ufficialedei processori Ryzen, AMD ha dichiarato che la microarchitettura Zen 2 è caratterizzata da un parametro IPC (Instruction per Clock, istruzioni per ciclo di clock) superiore del 15% e da un’efficienza energetica migliore del 75% rispetto alla precedente generazione Zen+. Si tratta di un risultato molto positivo e superiore alle aspettative, come dichiarato dalla stessa Lisa Su durante il keynote di Computex.
Il passaggio a un processo produttivo più raffinato, ma caratterizzato da una maggiore minuaturizzazione dei transistor, comporta inizialmente una riduzione delle frequenze operative rispetto alla medesima mircorarchitettura realizzata con transistor più grandi.


Questo accade perché transistor più piccoli richiedono una tensione minore per operare e più bassa è la tensione e minore è la frequenza operativa che è possibile raggiungere. In realtà i nuovi Ryzen vincono su tutti i fronti: utilizzano una tecnologià più avanzata rispetto alla generazione precedente, consumano meno, sono più efficienti e riescono a operare anche a frequenze maggiori. Ovviamente, solo la prova sul campo è in grado di dire qual è l’entità dei miglioramenti di prestazioni con le applicazioni reali.

AMD Ryzen 9 3900X 
AMD Ryzen 7 3700X
Benchmark e risultati
La prova dei processori Ryzen è stata l’occasione per rivedere la nostra suite di test. Oltre agli aggiornamenti dei benchmark che già utilizziamo da tempo, trovate anche qualche novità.
| PRESTAZIONI | ||||||||
|---|---|---|---|---|---|---|---|---|
| Ryzen TR 1950X | Ryzen TR 1920X | Ryzen 9 3900X | Ryzen 7 3700X | Ryzen 7 2700X | Ryzen 5 2600X | Ryzen 7 1800X | Ryzen 5 1600X | |
| BAPCo SYSmark 2018 (1.0.1.48) | ||||||||
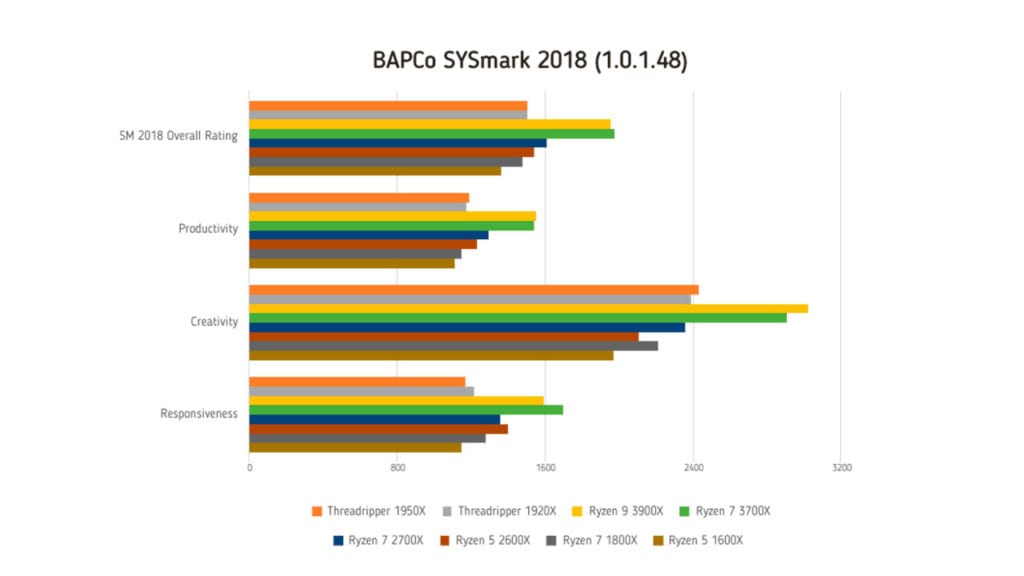
| SM 2018 Overall Rating | 1502 | 1506 | 1955 | 1976 | 1608 | 1538 | 1480 | 1361 |
| Productivity | 1190 | 1173 | 1551 | 1541 | 1296 | 1234 | 1146 | 1112 |
| Creativity | 2429 | 2391 | 3023 | 2906 | 2360 | 2104 | 2209 | 1971 |
| Responsiveness | 1171 | 1218 | 1593 | 1700 | 1359 | 1401 | 1280 | 1150 |
| BAPCo SYSmark 2018 (1.0.1.48) - Energy Consumption | ||||||||
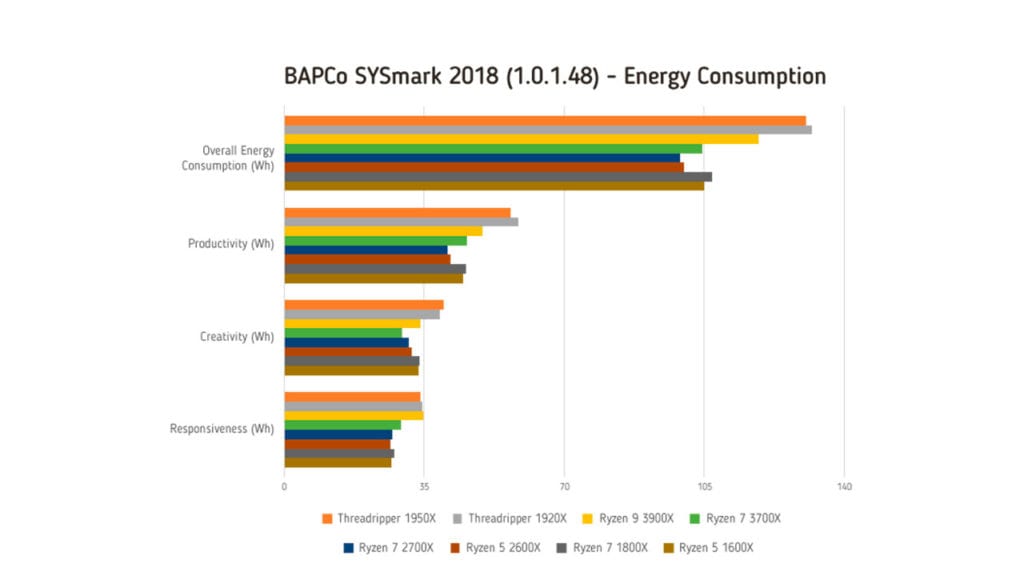
| Overall Energy Consumption (Wh) | 130.55 | 131.92 | 118.64 | 104.58 | 99.04 | 100.1 | 106.93 | 105.02 |
| Productivity (Wh) | 56.65 | 58.46 | 49.68 | 45.75 | 40.75 | 41.68 | 45.48 | 44.67 |
| Creativity (Wh) | 39.9 | 38.82 | 34.17 | 29.56 | 31.27 | 31.86 | 33.87 | 33.57 |
| Responsiveness (Wh) | 34 | 34.64 | 34.79 | 29.26 | 27.02 | 26.56 | 27.57 | 26.79 |
| UL Benchmark PCMark 10 (2.0.2115) | ||||||||
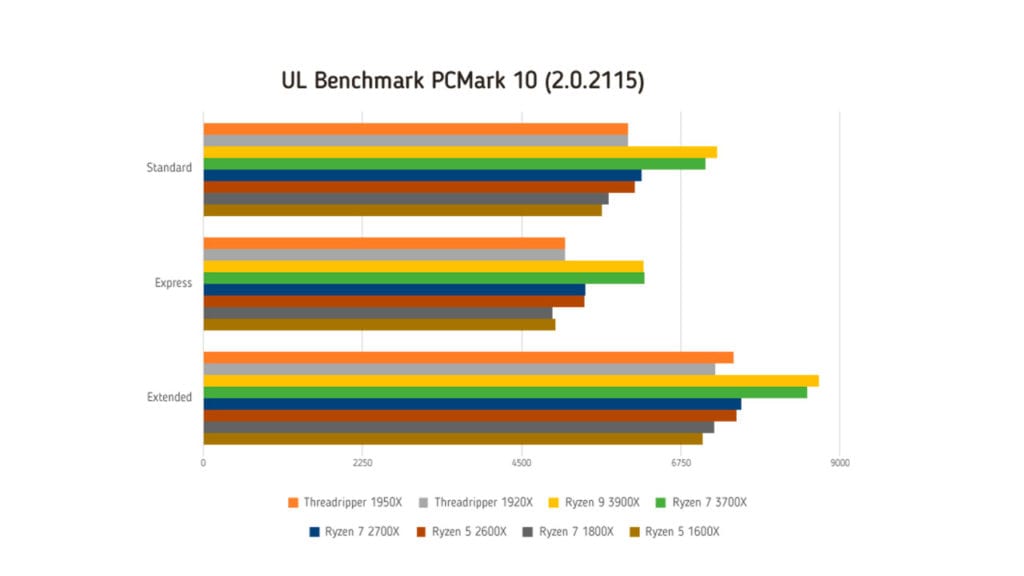
| Standard | 6002 | 5999 | 7263 | 7094 | 6196 | 6100 | 5724 | 5638 |
| Express | 5120 | 5113 | 6216 | 6236 | 5405 | 5391 | 4941 | 4980 |
| Extended | 7491 | 7230 | 8697 | 8530 | 7611 | 7532 | 7224 | 7053 |
| Geekbench 4.3.4 Pro | ||||||||
| Singolo core | 4703 | 4553 | 5797 | 5690 | 4892 | 4814 | 4514 | 4512 |
| Multi core | 35477 | 33177 | 46828 | 35877 | 27533 | 23221 | 25379 | 21257 |
| Maxon Cinebench R20 | ||||||||
| Singolo core | 406 | 404 | 488 | 502 | 435 | 423 | 387 | 385 |
| Multi core | 6591 | 5299 | 6950 | 4764 | 3911 | 3027 | 3604 | 2732 |
| Corona 1.3 Benchmark | ||||||||
| Rendering Ray/s | 6674580 | 5275220 | 6481570 | 4429700 | 3903120 | 2999520 | 3586580 | 2709950 |
| Rendering time (s) | 72 | 92 | 74 | 109 | 124 | 162 | 135 | 179 |
| Blender 2.79b - CPU Benchmark | ||||||||
| Gooseberry 1.0 (s) | 1310 | 1612 | 1258 | 1836 | 2153 | 2778 | 2333 | 3050 |
| Bmw27 (s) | 160 | 198 | 161 | 234 | 268 | 352 | 293 | 383 |
| Luxmark 3.1 | ||||||||
| Neumann TLM-102 SE - C++ | 5896 | 4590 | 6094 | 4311 | 3664 | 2735 | 3398 | 2514 |
| Hotel lobby - C++ | 2110 | 1704 | 2225 | 1510 | 1296 | 999 | 1155 | 888 |
| Agisoft Metashape Pro 1.5.2 | ||||||||
| Rock Model (s) | 311.9 | 310.4 | 234.7 | 255.5 | 301.2 | 329.6 | 327.3 | 358 |
| Rock Model Depth Maps (s) | 332.3 | 330 | 252.6 | 289.5 | 341.9 | 386 | 367.4 | 419.1 |
| School Map (s) | 1584.4 | 1638.6 | 1248.6 | 1362.8 | 1607.3 | 1764.7 | 1731.7 | 1908.1 |
| Handbrake 1.1.2 - Transcodifica | ||||||||
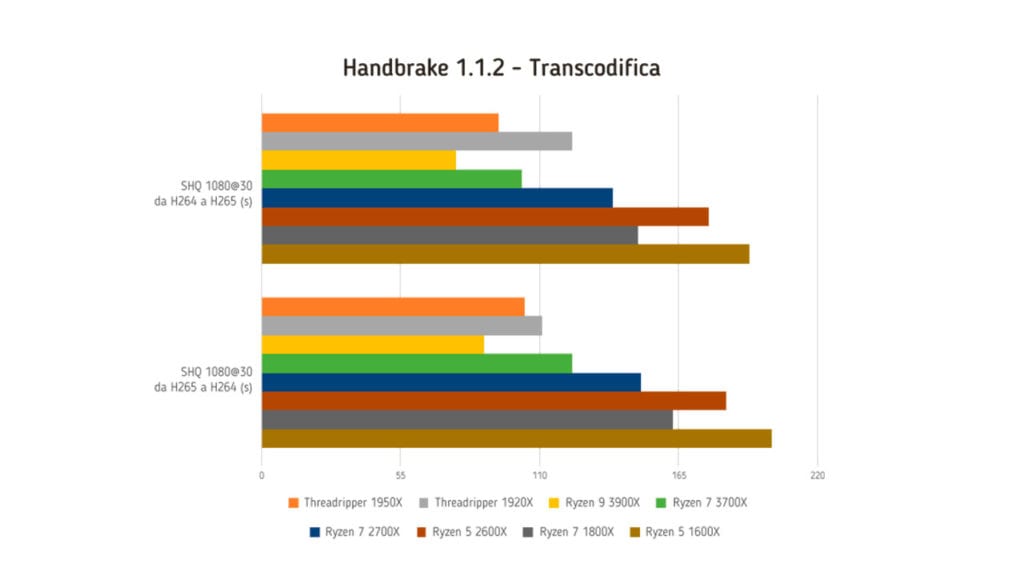
| SHQ 1080@30 da H264 a H265 (s) | 94 | 123 | 77 | 103 | 139 | 177 | 149 | 193 |
| SHQ 1080@30 da H265 a H264 (s) | 104 | 111 | 88 | 123 | 150 | 184 | 163 | 202 |
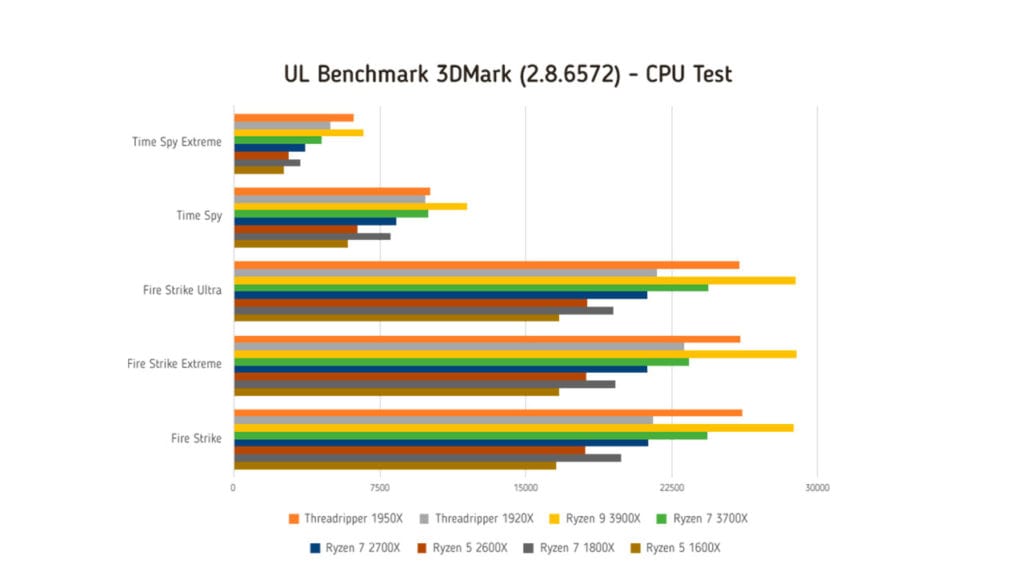
| UL Benchmark 3DMark (2.8.6572) - CPU Test | ||||||||
| Time Spy Extreme | 6164 | 4942 | 6639 | 4511 | 3650 | 2797 | 3401 | 2582 |
| Time Spy | 10104 | 9860 | 11963 | 10003 | 8351 | 6339 | 8025 | 5853 |
| Fire Strike Ultra | 25974 | 21729 | 28863 | 24386 | 21253 | 18140 | 19483 | 16720 |
| Fire Strike Extreme | 26026 | 23138 | 28924 | 23418 | 21259 | 18109 | 19598 | 16712 |
| Fire Strike | 26159 | 21534 | 28763 | 24360 | 21311 | 18045 | 19884 | 16560 |
BAPCo SYSmark 2018
La suite SYSMark realizzata da BAPCo riproduce, attraverso l’installazione di applicazioni reali (o parti di esse), l’utilizzo di un computer durante l’esecuzione di tre scenari: Productivity, Creativity e Responsiveness. Il primo scenario esegue elaborazione di testi, manipolazione di dati in fogli di calcolo, gestione email, preparazione di presentazioni, sviluppo di codice, installazione di applicazioni e archiviazione di file. Il secondo test è incentrato sull’editing e la catalogazione di immagini e montaggio video. Il terzo test misare la reattività del sistema durante l’esecuzione di più applicazioni.
Tra gli applicativi utilizzati figurano le suite Adobe, quella Microsoft Office, WinZip e Cyberlink PowerDirector. I risultati sono ottenuti dopo l’esecuzione di un giro di condizionamento del sistema e di almeno un giro completo dell’intera suite. L’utilizzo di un wattmetro Watts Up? Pro consente di rilevare i consumi fondendo valori parziali e il totale. I risultati finali sono normalizzati rispetto al valore 1.000 ottenuto con una configurazione così composta: processore Intel Core i3 7100 a 3,90 GHz, 4 Gbyte di memoria Ddr3, processore grafico integrato Intel HD Graphics 630, disco Sata in formato M.2 da 128 Gbyte e sistema operativo Microsoft Windows 10 Pro a 64 bit (build 1709).
UL Benchmark PCmark 10
La suite PCMark 10 valuta le prestazioni attraverso quattro diversi scenari: Standard, Express, Extended e Application. La modalità Standard valuta le prestazioni in uno scenario aziendale con applicazioni per l’ufficio; questa modalità prevede l’avvio di applicazioni, la navigazione web, collegamenti in videoconferenza, scrittura, utilizzo di fogli di calcolo, editing di immagini e video, così come la produzione di rendiring e la visione di progetti. La modalità Express si concentra sulla produttività personale: avvio di applicazioni, navigazione web, collegamenti in videoconferenza, scrittura e utilizzo di fogli di calcolo. Lo scenario Extended, infine, copre la più ampia varietà di attività e applicazioni; ai test della modalità Standard si aggiunge la valutazione delle prestazioni grafiche grazie al test FireStrike della suite 3Dmark. La modalità Application – non la eseguiamo vista la presenza del test SYSMark di BAPCo – richiede l’installazione della suite Microsoft Office ed esegue test di prestazioni in ambito di produttività personale e aziendale con le applicazioni reali. I risultati sono valori sintetici normalizzati in base al punteggio di tre diverse configurazioni, una per ogni tipologia di test.
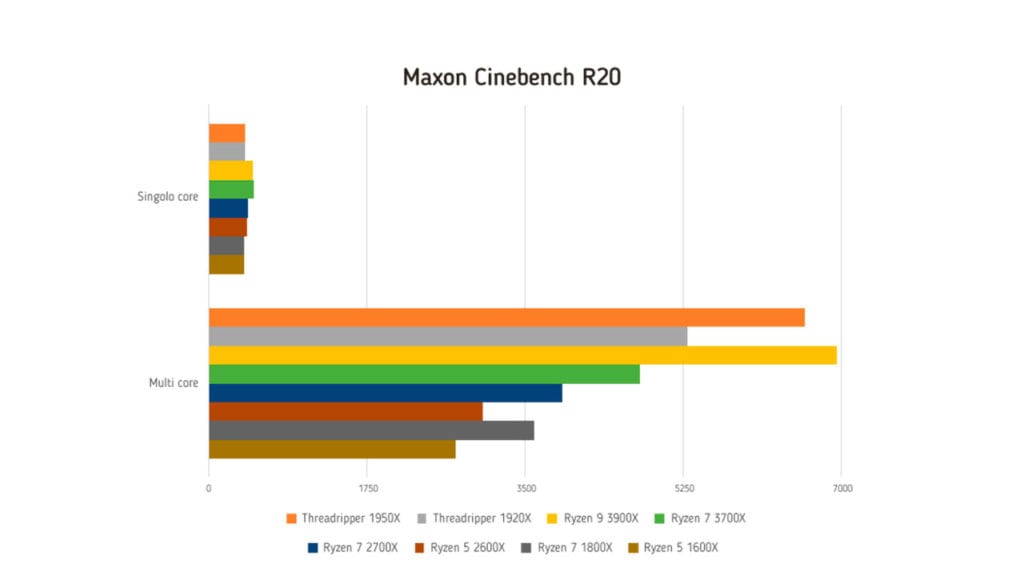
Cinebench R20
Cinebench è un benchmark che si basa sull’applicazione reale di animazione Cinema 4D di Maxon utilizzata negli studios cinematografici. Il test esegue il rendering di un’immagine con qualità foto realistica e utilizza funzionalità che mettono a dura prova la potenza di calcolo della Cpu: funzioni di riflessione, ambient occlusion, illuminazione e shader procedurali.
Il benchmark utilizza al massimo la potenza di calcolo del processore impegnando tutti i core e i thread disponibili.
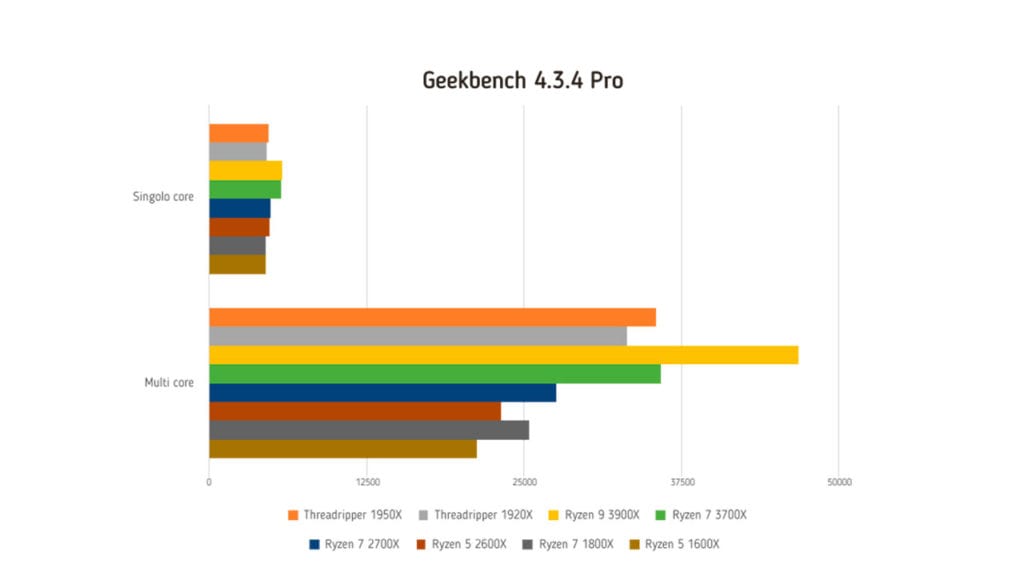
Geekbench 4.3.4 Pro
Geekbench è un test multipiattaforma prodotto da Primate Labs che valuta le prestazioni di Cpu e Gpu. Il benchmark fornisce due risultati: uno per i carichi di lavoro eseguiti su un singolo core e un secondo per quelli eseguiti sfruttando tutti i core di calcolo disponibili. Ogni sezione dei benchmark prevede l’esecuzione di elaborazioni che utilizzano algoritmi di crittografia, elaborazioni con numeri interi, elaborazioni in virgola mobile e misurazioni sulle prestazioni di accesso e utilizzo della memoria. Ogni test riproduce carichi di lavoro o applicazioni per fornire risultati indicativi delle prestazioni reali del processore in esame.
I risultati forniti sono calibrati rispetto al punteggio base (4.000) ottenuto con un processore Intel Core i7 6600U. A un risultato superiore corrispondono prestazioni superiori e l’andamento è lineare, ovvero a un risultato doppio corrispondono prestazioni doppie.
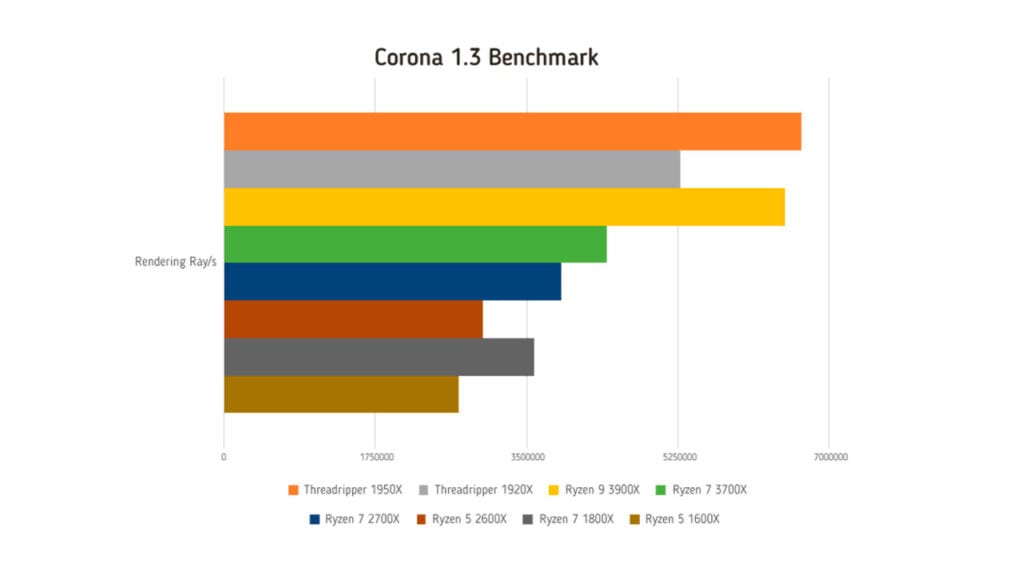
Corona 1.3 benchmark
Questo benchmark si appoggia al motore Corona Renderer 1.3, una versione non più aggiornata di questo motore di rendering fotorealistico che oggi è disponibile in versione 1.7 sia come plugin sia come software indipendente. Il motore di rendering aggiornato offre prestazioni migliori in ambito lavorativo, mentre il benchmark è stato fermato alla versione 1.3 per mantenere confrontabili tra loro i risultati passati con quelli presenti.
Il benchmark sfrutta tutti i core di calcolo del processore per generare un’immagine filale, fornendo come risultato il numero di raggi elaborati al secondo dall’algoritmo ray tracing e il tempo complessivo necessario per portare a termine il rendering.
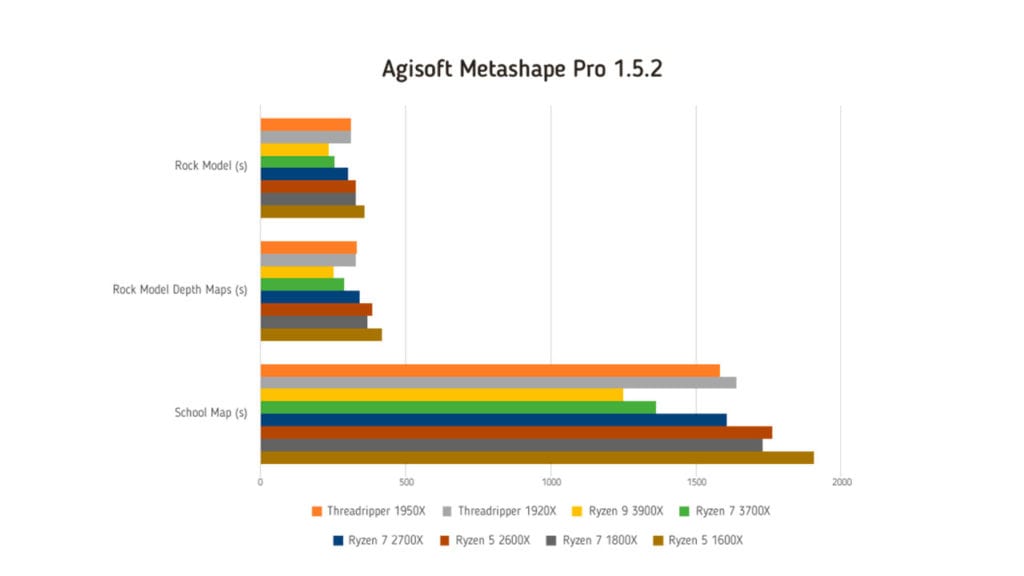
Agisoft Metashape 1.5.2 Pro
Metashape di Agisoft è un’applicazione sviluppata per la fotogrammetria, una tecnica di rilievo che sfrutta l’analisi di foto stereometriche. La fotogrammetria è impiegata in cartografia, topografia e in architettura. Il flusso di lavoro prevede l’importazione di una serie di foto, la definizione di punti di misurazione e l’elaborazione delle immagini per generare un modello tridimensionale. Una volta generato, il modello può essere esportato e utilizzato con altri software. Metashape sfrutta la potenza di calcolo della Cpu, della Gpu e algoritmi di intelligenza artificiale.
Per la prova utilizziamo il modello di benchmark creato da Puget System e scaricabile a questo link.
Handbrake 1.1.2
Handbrake è un software open source per la conversione di file video nei formati H.265, H.264, H.265 MPEG-4 e MPEG-2, VP8 e Theora. Per la prova abbiamo eseguito due test su ogni processore: il primo prevede la transcodifica di un file video 4K dal formato di codifica H.264 a quello H.265 utilizzando il codec software che utilizza unicamente i core del processore. Il secondo test prevede invece la transcodifica di un file video dal formato H265 a quello H.264, anche in questo utilizzando il codec software che opera solo sui core del processore. Il test fornisce come risultato il tempo necessario a portare a termine l’operazione di codifica e per questo motivo a un tempo inferiore corrispondono prestazioni superiori.
3Dmark – CPU
La suite 3DMark è progettata per misurare e analizzare le prestazioni in campo grafico di computer desktop e portatili, ma anche di smartphone e tablet grazie al supporto multipiattaforma. Il 3DMark prevede un set di scenari pensati in modo specifico per analizzare le prestazioni di sistemi dotati sia di una limitata capacità di calcolo sia di quelli più carrozzati e in grado di eseguire applicazioni grafiche per la realtà virtuale. Nelle prove relative ai processori eseguiamo i test Time Spy Extreme, Time Spy, Firestrike Ultra, Firestrike Extreme e Firestrike, pubblicando i risultati dei sottotest relativi alle prestazioni legate ai calcoli fisici e quindi relativi agli algoritmi eseguiti solo sui core del processore e non sulla scheda grafica. In questo caso a risultati maggiori corrispondono prestazioni superiori.